A short post argued this week that reliable agents need deterministic control flow, not more prompts. The argument is correct. The line that lands hardest in the piece is the one about a programming language where statements are suggestions and functions return "Success" while hallucinating. That is the model when prompt chains carry the control flow; it is also a perfect description of why those systems collapse as complexity grows.
The piece closes with three options for what to do about it: a babysitter (human in the loop), an auditor (exhaustive end-to-end verification after the run), or prayer (vibe-accept the outputs). It frames those as the alternatives left after the prompt chain has already failed.
There is a fourth option, and it is the one the same piece was arguing for earlier. Tests.
What the fourth option actually is
Tests in the unflashy software-engineering sense. Programmatic verification at every step. Schema checks. Range checks. Reference checks. Predicate assertions over the LLM's output before the next code branch executes. Not ask the model nicely to format its answer correctly. Not log the response and read it later. The next step does not run until the previous step's output passes a contract you wrote in code.
Calling them tests matters more than the technical content. Engineers already have a mental model for tests. They know how to write them. They know how to run them. They know that broken tests block deploys. They know that a feature without a test is a feature that will silently break. The infrastructure for tests — assertion libraries, CI, coverage tools, test runners — already exists. We are not inventing a new discipline. We are applying an existing one to the new untrusted-input surface, which is the LLM's output.
The babysitter / auditor / prayer trichotomy describes a system that has decided not to write tests. The fourth option is the option of writing them.
This is what most of the production controls already are
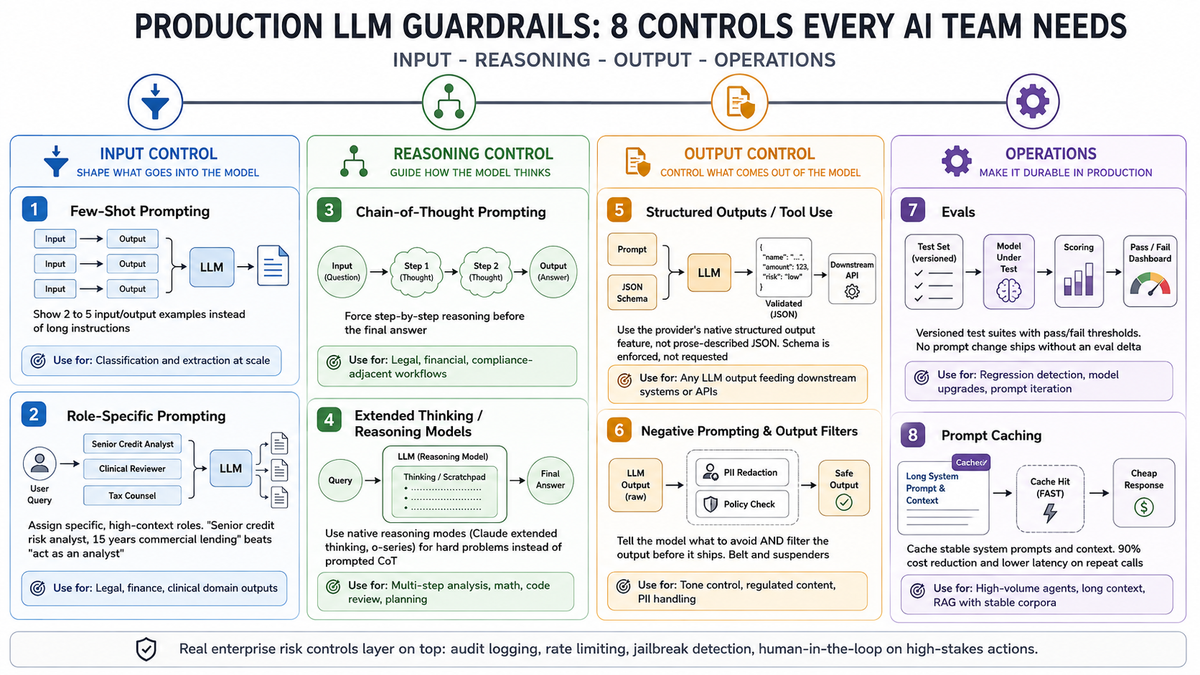
Most of the eight production LLM controls I wrote about yesterday are tests in disguise. Not all of them. But most.
- Structured outputs / tool use is a schema assertion at the API boundary. The provider rejects malformed output before it reaches your code. You did not have to write the parser-with-retry. The schema is the test.
- Negative prompting plus output filters is a predicate check after the response. The filter runs as code, against the response, before the response is allowed downstream. Belt is the prompt; suspenders is the test.
- Evals are versioned test suites with pass/fail thresholds. Already named "tests." Already gated to deploy. The model gets upgraded; the eval suite runs; pass-or-block. Same shape as a regression test for any other component.
- Chain-of-thought has a test analog too: assert the response contains the intermediate reasoning before accepting the final answer. Most teams skip this assertion and accept whatever comes back. The contract was implicit; the violation goes unnoticed.
The other three controls — few-shot prompting, role-specific prompting, extended thinking — are about shaping the input and the model's behavior. They reduce the rate at which tests fail. They do not replace the tests themselves.
The agent-pipeline piece argued the same thing at the action layer
Last Tuesday's piece on the agent action pipeline named six artifacts that should sit between an agent and the infrastructure it can damage. Every one of them is a test, in the same expanded sense.
- Dry-run by default for destructive operations is an assertion that a human (or an approval agent) signs off before the destructive call executes. The assertion blocks the call.
- Blast-radius declarations per task is a runtime check that the tool scope matches what the task declared. The check fails the call if the scope was exceeded.
- Proof chains are append-only logs of every action with its inputs, intent, and outcome. They are the audit trail of which assertions passed or failed and when.
- Human-in-the-loop above a threshold is a conditional assertion: below the threshold, the system runs autonomously; above it, the assertion routes to a human for explicit pass/fail.
PocketOS lost their database because none of these tests were wired in. The agent's call to delete a Railway volume passed every check the system actually had — there were no checks. The fix is not a more emphatic system prompt. It is a runtime assertion that the call is allowed.
The honesty test
For any given LLM call in your system, can you write down the assertion that would let the next step execute?
If yes, you have a test. The test is the contract. The test is what makes the system reason about itself and refuse to keep going when reality has diverged from the contract.
If no, you have one of the original three options. Babysitter — a human is the assertion, manually, in real time. Auditor — the assertion runs after the fact, when the damage is already done. Prayer — there is no assertion; the system runs and you find out later if it was wrong.
The diagnostic is easier to apply than to evade. Pick any LLM call in your stack. Write down the assertion that would unblock the next step. If you cannot, you are praying. The control flow the original argument is pointing at is not control flow in the abstract. It is the specific code that runs the assertion before the next call goes out.
Why this frame is operationally useful
Tests tells engineers what to build. Deterministic control flow tells them why. Both are necessary, but only one is something a junior engineer can ship by Friday.
Engineers know how to write a test for a function whose return value is uncertain. They have done it for every flaky external API integration they have ever shipped against. The LLM is another flaky external API. The output is another value to assert against. The test failure is another reason to back off, retry, or escalate. Once the team accepts this framing, the work is straightforward. Not easy — straightforward. Pick a call. Write the assertion. Wire the failure path.
The piece I started this on is right that prompt chains hit a ceiling. The fix is not more prose, and not more babysitting. It is the same move every reliability discipline has made for fifty years: write the test, gate the call, fail loud when reality breaks the contract.
Babysitter, auditor, prayer. Or tests. Pick the fourth one.